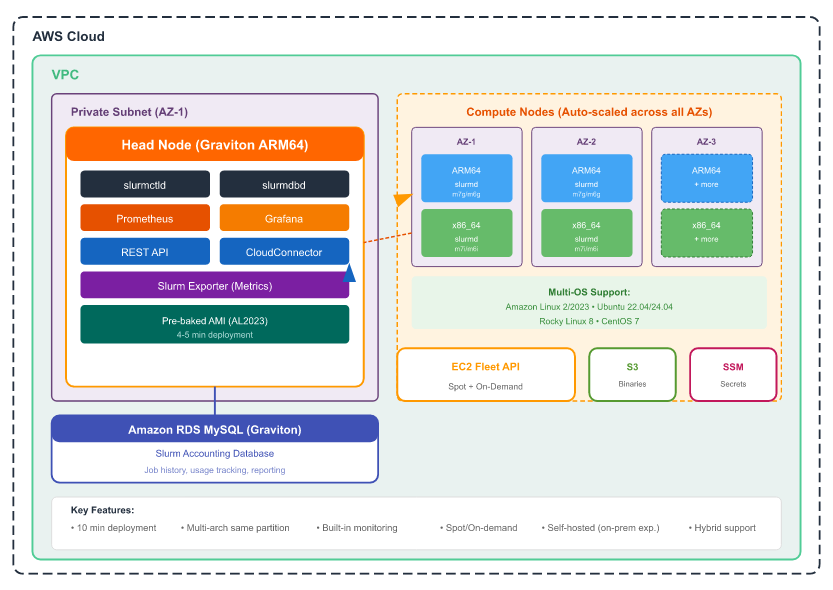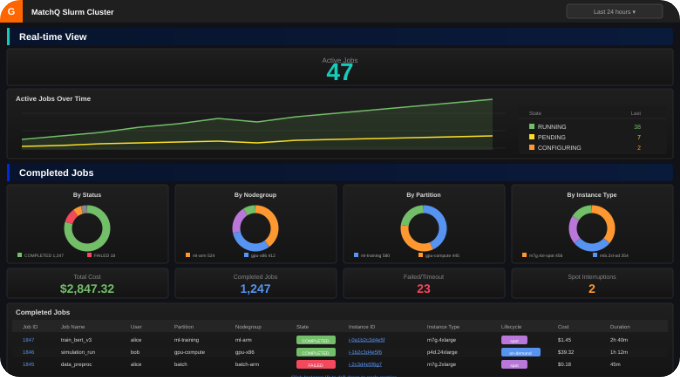
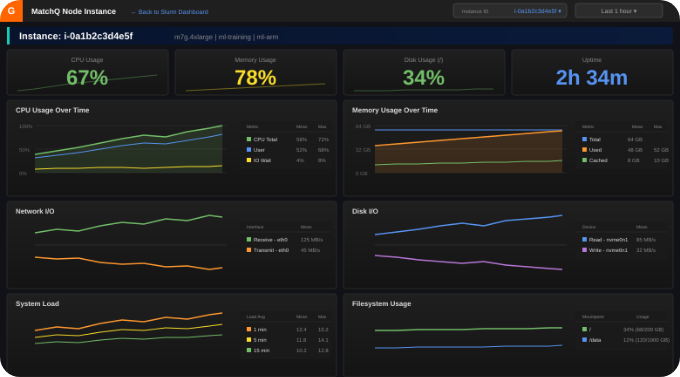


Built and Backed by HPC Engineers
MatchQ isn't built by a product team that just read the Slurm docs. It's built by Modality Cloud Services, an AWS Advanced Consulting Partner whose engineers have been designing and supporting HPC on AWS, and specifically Slurm on AWS, for many years across semiconductor, life sciences, AI, and media workloads.
When you run MatchQ, you get direct access to the engineers who built it. People who work with Slurm clusters daily, from debugging complex EC2 startup issues to designing partition strategies and optimizing Spot usage. Whether you're migrating from PBS or Sun Grid Engine, building a hybrid cluster that manages on-prem and cloud compute from a single controller in your VPC, or scaling an existing environment, Modality's team works alongside yours.